On Service Location
I have some pretty strong feelings about the use of the Service Locator pattern in the software we build. They go along the lines of ‘why would you ever use it?’ and possibly (and somewhat mellow dramatically) rocking slowly backwards and forth in the corner of the shower after being exposed to it. So to ease my pain, and perhaps yours, I have compiled an explanation of why I feel so intolerant toward this pattern.

Coupled To The Service Locator
I’ll wager that you have heard about loose coupling in software. It’s something that developers from all walks of life can agree on – we should strive to build loosely coupled software. We do this for many reasons, to achieve composability, for ease of maintenance, testability and more generally, the sanity of the other developers on your team.
A technique used to achieve loosely coupled components is dependency injection. Dependency injection can come in many forms. From dependencies being provided at object construction time, all the way to being resolved, via a service locator, during the execution of a some operation on that object.
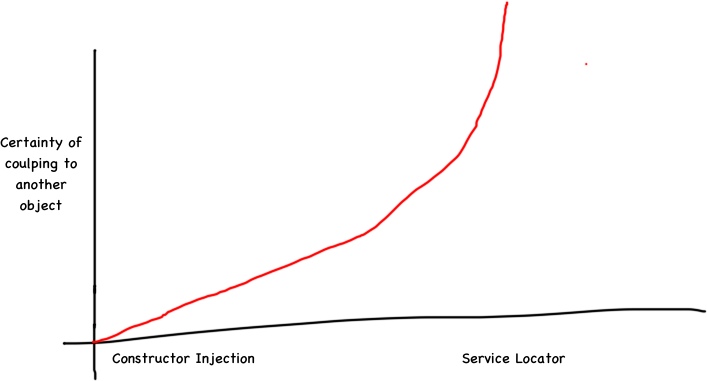
By injecting dependencies when an object is constructed, you have the most chance of successfully building loosely coupled applications.
Somewhere in the middle, is property injection. Depending on how your property injection is implemented your chances of building loosely coupled components vary.
And at the very extreme – The Service Locator. When you implement a call to a static service locator during the execution of a methods, the net result is a hard coupling to the service locator.

Am i loosely coupled? One could argue that our class is loosely coupled because is not reliant on a given implementation of the ILooselyCoupledDicisionEngine, and yes strictly speaking, this is true. But in regard to the how coupled this object is to other objects, this is a moot point.
The base level of coupling has already been set, we are already coupled to our static service locator. LooselyCoupledThing is directly coupled to the ServiceLocator object.
LooselyCoupledThing is unable to be an object in its own right, without relying on its dirty friend the service locator to help it along in life.
By using the ServiceLocator object you have introduced coupling where your goal was to reduce it.
Unit Tests Scream Warning Signs
One of the first things I notice when working with an application which has heavy use of a service locator, is the extra unit testing baggage which comes with it. Usually there is a marked lack of discoverability of dependencies, and over time unit tests projects seem to grow in complexity until they are more complex than what they are testing.
Unit tests are a measuring stick for complexity in the code they are testing. The amount of setup work involved with getting a test to pass can be a strong indication for things like poor encapsulation and separation of concerns. When your unit test requires a full set up of your service locator object, alarm bells should be sounding, perhaps your components are not following the principals of SOLID as closely as they could. Let me explain.
As an example, lets define a class to represent a car. I’ll admit, I don’t know lot about cars so this could get interesting.

It doesn’t do a lot and its super easy to write a unit test for.
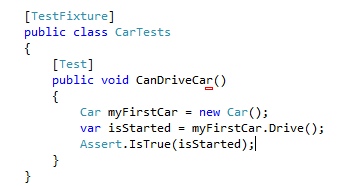

All is well in the world, the test passes, and the car is able to drive around.
Until someone who is very knowledgeable about cars spots my nieve implementation, and decides that a car needs an engine to start. The engine is resolved using our (dirty) friend, the service locator.
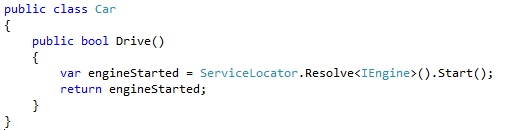
And now, the test fails. Our static service locator is unable to resolve our IEngine implementation.

But wait, our car is able to driven when our application runs outside of the context of the test, so what is different here? In the context of the test, we have not registered any of our dependencies with our service locator. Lets set them up now to get our test to pass.


For every new dependency which is resolved in line via a service locator like this, we need to ensure that our test suit has a corresponding dependency set up in its registry.
Hopefully you can see the problem here. This is a very trivial example, in the real world you can have many hundreds of services wired up in your unit test project like this. I commonly see *monolithic* test base classes, which before the start of *every* test fixture (or worse, an individual test) will set up every possible dependency that could be requested from the service locator object.
This is massive overhead, for both the running time of your tests and for ease of understanding of what is actually being tested.
These kinds of unit test are telling you two things
- That you are tightly coupled to your service locator.
- That you are violating the principal of single responsibility.
The car object has a single responsibility – to drive. It should not be involved with the resolution of its engine. Imagine if every time you had to drive into work you first had to find the correct engine for your car, and assemble the car with said engine before you could start it. This makes no sense conceptually, yet this is exactly the kind of design our service locator has given us.
So following that logic – when we call our cars constructor, we should have everything we need up, set up and ready to go, so that our object is ready to carry out its behaviours.

Ok – its a little better. But not much. We are still coupled to our service locator object and our test still require our service locator object to be bootstrapped and ready to go.

Lets turn our ServiceLocator object into an injectable dependency. I can almost hear proponents of the service locator pattern nodding in agreement. But the question is, is this any better? Its definitely better than using a static service locator. We can easily discover when we construct a car object that it takes an IServiceLocator dependency.
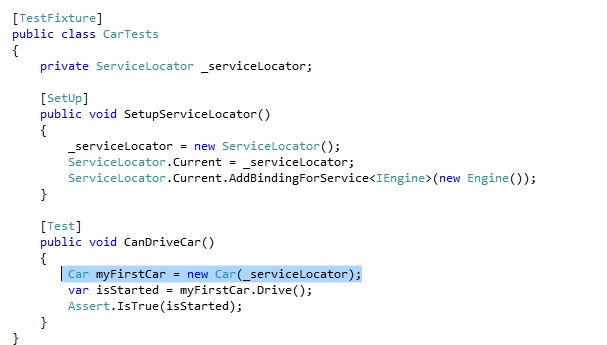
But, this is starting to feel like we need to write a lot of ‘plumbing code’ in our unit test. The purpose of this test is to assert that we are able to drive our car, so why does it feel like all we are really showing is that we are able to set up a service locator?
Over half the lines of code in this test class are about our service locator! Over half the lines of code in this test class are concerned with plumbing.
Just mock the service locator! O_O

Our test class looks a little cleaner. But, is this enough? What happens when we decide that in order to drive, not only do we need an engine, but we also need some wheels?

Remember our test?


Our service locator mock knows nothing about our flash new wheels, and the test fails. The point here is at compile time we could not discover the new dependency on wheels. Our test are indicating that injecting a service locator object is a brittle approach, because we can never be clear about the intent of the car object.
A much simpler approach, is to be explicit and inject our dependencies up front.

Now we know, if we want to construct a car, we will need an engine and a collection of wheels. And when someone decides we need a radio in order to drive our car, a compile error will warn us a new dependency has been added to our car.
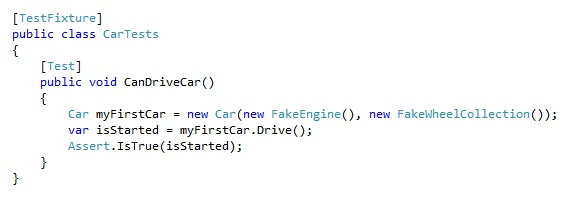
And look at our test! Much simpler, much more explicit, and it only tests one thing!
Lifetime Management Hell
A commonly overlooked side effect of introducing Inversion of Control to your software, are changes life time management of objects. A lack of understanding of this side effect, combined with excessive or blind use of a service locator object, can have unexpected and even catastrophic side effects.
To understand what I mean by this lets look at a very simple example – a sloth repository.
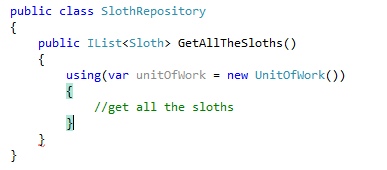
In this example, when we want to query our datastore for all the sloths, we have direct control over when our unit of work gets disposed. Or in other words, we can manage the lifetime of the unit of work object.
If we choose to inject the unit of work via our inversion of control mechanism, we loose the ability to choose when the unit of work gets disposed. We can no longer wrap it up in a nice using statement. The unit of work needs to disposed of by the object which is responsible for constructing our repository.

If you are using an IOC container then it will be its responsibility to coordinate the call to Dispose. But – how can the container possibly know when unit of work is ready to be disposed of?
Luckily, the cleaver guys and gals who have created your IOC containers understand that out of inversion of control naturally arises the need to manage object scope and lifetime. Modern IOC containers provide out of the box support for managing the lifetime of an object, in the scope of a thread, an http request or even in singleton scope. Modern inversion of control containers are smart enough to cover almost any lifetime scope we can dream up.
Nicholas Blumhardt covers this in more detail in this excellent blog post if these concepts are new to you, I strongly recommend reading his description.
So what about the service locator’s pattern? When calling into your service locator’s in line in your class, what lifetime scope should be used to request the object? The parent object has already been constructed and the information the container needs to give you a correctly scoped dependency is gone. The service locator is highly likely to give you an object which does not match the scope of its parent.
How can getting the incorrectly scoped object have catastrophic effects?
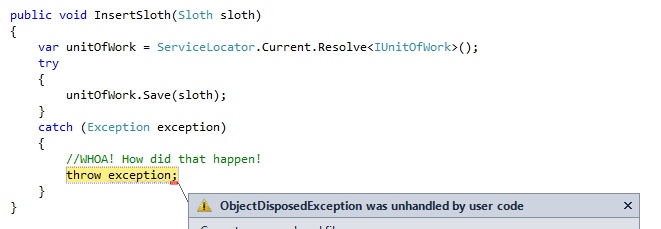
In a web app, a unit of work is something that makes sense to be scoped per HTTP request. If our service locator resolves an incorrectly scoped unit of work (i.e. one outside the current HTTP request) all kinds of funny things can start happening. In the above example one HTTP request thread is inserting a sloth. When save is called, we find that a different HTTP request thread has already disposed of our unit of work.
The example is one that you would probably catch pretty early on, as it throws an exception, but you can imagine that not all cases will not throw exceptions but silently work without any obvious indication of incorrect functionality.
Imagine a simple attribute (created in singleton scope) which is used to validate user permissions.
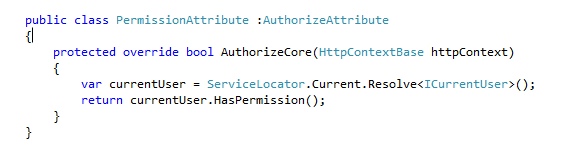
It uses a service locator to resolve the current user object. It then uses this object to validate that the current user had permission to do something. Everything works great. Until you check the debug logging under load. The current thread user, and the object the attribute was using to validate permissions were actually different! The service locator knows nothing about what scope it should resolve the current user from. Some users get denied when they had permission, and some users are let through when in reality they shouldn’t have. Eeek!
It is super important that when using techniques such as inversion of control that we understand the implications to life time management. If we don’t understand this concept, and we blindly use the service locator pattern, there will be trouble in your future.
When is it ok?
Never.
Ok, thats a bit of stretch. Sometimes you cant avoid it.
There are generally two broad cases where you might need to break out and call the service locator.
- When your class interactions have been designed in a way which are not easily injectable. In this case the advice is refactor your code to support it.
- When you are using a framework component which does not support constructor injection – which I often find cases for in ASP.NET
There is a third, more specialised case, where I can see an argument to use a service locator object. When building libraries which have swappable components. This case would be a good use (the only one I can think of) of the common service locator project http://commonservicelocator.codeplex.com What this would enable developers consuming your library or framework is to plug in their dependencies without needing to know the implementation details of your own IOC container. However, this should be the extent of its use. The library or frameworks internal code should still follow the principals of SOLID. There is still no need to have service locator calls sprinkled through out its code base.
During the description of testing a Car class I eluded to the fact that when using service location inline the car is responsible both for its own behaviour and its construction. This is the fundamental difference between dependency injection, and service location. In dependency injection, all objects are created externally, dependent objects are given to objects which need them. In service location, dependencies are requested. As much as I hate to admit, I can see that in some application architectures, the requesting of dependencies might be more appropriate. Though I can not see how this would ever need to be the sole way of injecting dependencies, throughout an application.
Final thoughts
The heavy use of service location in your code is generally a sign of few things. A tight coupling between objects, and objects resolution, objects which have more than one single responsibility, and a mine field of lifetime management hell.
If you find yourself in a position where your test projects require a similar level of maintenance and are of comparable complexity to you application code, have a good look into if you have baked in service locator object as a core concept in your application.
When we write software, we should be concerned the the business functions we are trying to solve – our core concepts are our business objects, not a service locator.
[![Kick It][27]][27]